728x90
반응형
✅ JPA?
Java Persistence API- 자바 진영의 ORM 기술의 표준
- ORM이란?즉, 객체 관계 매핑이다.ORM이라는 프레임워크가 중간에서 매핑하는 것
- 대중적인 언어에서는 대부분 ORM기술이 존재하여, 데이터베이스와 어플리케이션 간의 인터페이스를 보장한다. (ex.
python sqlalchemy) - 객체는 객체대로 설계 / 관계형 데이터베이스는 관계형 데이터베이스대로 설계
Object-Relational Mapping
✅ JPA의 동작
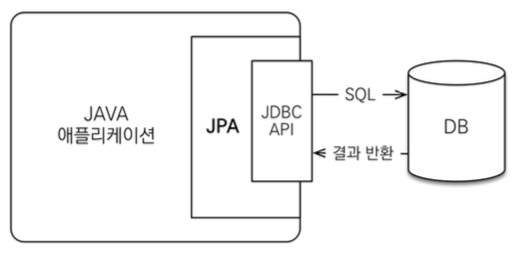
- 어플리케이션과 JDBC 사이에서 동작한다.
✅ 표준 명세
- JPA는 기본적으로 인터페이스의 모음이다.
- 이 JPA 표준 명세를 구현한 3가지 구현체가 존재한다.
HibernateEclipseLinkDataNucleus
✅ JPA 사용 이유?
- SQL 중심적인 개발에서 객체 중심으로 개발이 가능해진다.
- 생산성
- 유지보수
- 패러다임 불일치 해결
- SQL 방언 처리 기능 등으로 패러다임의 불일치를 해결한다.
- 성능
- 1차 캐시 등 다양한 이유로 성능상의 이점을 제공한다.
- 데이터 접근 추상화와 벤더 독립성
- 표준
🌱 생산성
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName(“변경할 이름”)
- 삭제: jpa.remove(member)
- JPA의 간단한 표현으로 CRUD를 손쉽게 구현할 수 있다.
🌱 유지보수
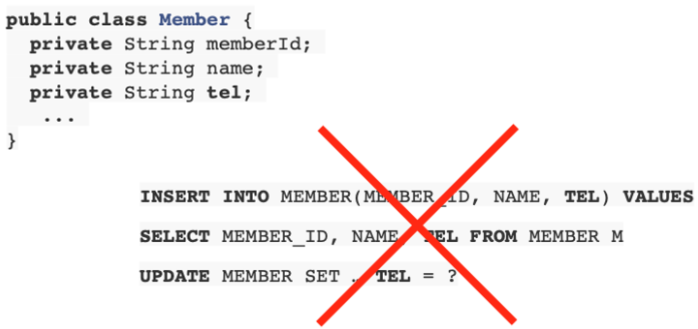
- JPA 필드만 추가하면 SQL은 JPA가 알아서 처리해준다.
🌱 패러다임 불일치 해결
💎 JPA와 상속
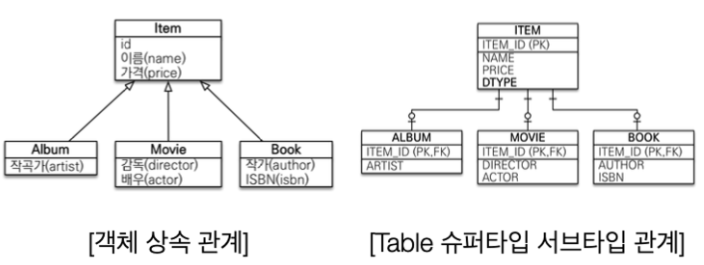
- 상속 구조를 갖는 데이터 모델에서 용이하다.
- 개발자가 할 일은
jpa.persist(album);,jpa.find(Album.class, albumId);뿐이다. - 나머지는 JPA가 처리해준다.
INSERT INTO ITEM ...INSERT INTO ALBUM ...- or
SELECT I.*, A.* FROM ITEM I JOIN ALBUM A ON I.ITEM_ID = A.ITEM_ID
💎 JPA와 연관관계
member.setTeam(team);
jpa.persist(member);- 연관관계에 있는 두 객체에서 저장하고 영속성 컨텍스트 처리 시, 더티 체킹에 의해 양쪽 객체에 반영(저장)된다.
💎 JPA와 객체 그래프 탐색
Member member = jpa.find(Member.class, memberId)
Team team = member.getTeam();- 연관관계에 있는 두 객체에서 쌍방으로 탐색할 수 있다.
💎 JPA와 비교하기
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId);
Member member2 = jpa.find(Member.class, memberId);
member1 == member2; //같다.- 동일 트랜잭션에서 조회한 엔티티는 같은 값임을 보장한다.
🌱 성능
- 1차 캐시와 동일성(identity) 보장
- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
- 지연 로딩(Lazy Loading)
💎 1차 캐시와 동일성(identity) 보장
- 같은 트랜잭션 안에서는 같은 엔티티를 반환한다.
- 약간의 조회 성능 향상
- DB Isolation Level이 Read Commit이어도 어플리케이션에서 Repeatable Read 보장
- JPA는 영속성 컨텍스트 내에 1차 캐시를 보유한다.
- 한 트랜잭션 내에서 처음으로 조회가 들어오는 엔티티에 대해, 1차 캐시에 존재하면 이를 반환한다.
- 아니라면 데이터베이스에서 꺼내오고, (SQL 실행) 이를 1차 캐시에 저장하고 이를 반환한다.
- 즉, 아래와 같은 구문에서 SQL은 단 한번만 실행된다
String memberId = "100"; Member m1 = jpa.find(Member.class, memberId); //SQL Member m2 = jpa.find(Member.class, memberId); //캐시 println(m1 == m2) //true
💎 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
- 트랜잭션을 커밋 (
tx.commit()) 할 때 까지INSERT SQL을 모은다. - JDBC의 BATCH SQL기능을 사용하여 한번에 SQL을 전송한다.
- 즉,
em.persiste(entity)를 통해 영속성 컨텍스트에 저장한다고 해서 바로 SQL을 실행하는 것이 아니다. em.persist(memberA); em.persist(memberB); em.persist(memberC);//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다. //커밋하는 순간 데이터베이스에 INSERT SQL을 모아서 보낸다. transaction.commit(); // [트랜잭션] 커밋UPDATE, DELETE SQL도 마찬가지이다.transaction.begin(); // [트랜잭션] 시작 changeMember(memberA); deleteMember(memberB); 비즈니스_로직_수행(); //비즈니스 로직 수행 동안 DB 로우 락이 걸리지 않는다. //커밋하는 순간 데이터베이스에 UPDATE, DELETE SQL을 보낸다. transaction.commit(); // [트랜잭션] 커밋
💎 지연 로딩(Lazy Loading)
- 지연 로딩 : 객체가 실제로 사용될 때 Database에서 로딩한다.
- 즉시 로딩 : JOIN SQL을 통해 연관된 객체를 미리 조회한다.
🌱 데이터 접근 추상화와 벤더 독립성
💎 데이터 접근 추상화
- 개발자는 SQL 쿼리를 직접 작성하는 대신, JPA가 제공하는 메서드를 사용하여 데이터를 조작한다.
- 이는 개발자가 데이터베이스에 대한 세부적인 사항에 대해 신경 쓰지 않고, 객체 지향적으로 프로그래밍할 수 있도록 한다.
💎 벤더 독립성
- 어떤 데이터베이스를 사용하든, JPA는 데이터베이스의 구현체에 상관없이 이를 번역하여 개발자가 특정 데이터베이스에 종속되지 않도록 한다.
🌱 표준
- JPA는 표준이다!
Ref
김영한 강사님, JPA 프로그래밍 - 기본편
감사합니다.
728x90
반응형
'Dev > Spring' 카테고리의 다른 글
| 연관관계 매핑(단방향) (0) | 2023.11.21 |
|---|---|
| 변경 감지(Dirty Checking) (0) | 2023.11.20 |
| 영속성 컨텍스트란 (0) | 2023.11.20 |
| 준영속과 변경감지 (0) | 2023.10.25 |
| [스프링 핵심 원리] Bean Scope (0) | 2023.09.30 |